Contents:
- Background
- Questions
- Starting out: Are you scared of spiders?
- First result set: Analyze this.
- Trucking on: Or rather, how to?
- Renewed methods (unleash the beast)
- Unicorn Sighted
- If at first you don't succeed...
- Second result set
- Third result set
- Answers to the questions
- Conclusion
- Software
- Sources
- Bit.ly - From their website: "bit.ly allows users to shorten, share, and track links (URLs)." So you can take a link like http://www.google.com/#hl=en%26source=hp%26q=what+the+hell+is+bit.ly and turn it into http://bit.ly/9WSN6Q. This is useful for IM, texting, twitter, all those other fancy things people are using.
- Spider / Crawler - An automated application that methodologically browses the web for data. This is how Google, Yahoo, et al find websites, pictures, text, and so forth gather data to index for their search products.
- Perl - A programming language.
- TLD - top level domain. In ewams.net the TLD is .net. In google.com the TLD is .com. Others include: .ly, .it, .org, .gov, .eu, etc.
- URL - uniform resource locator. Put simply, the website address.
- MySQL - An open source relational database software suite.
- Amazon Elastic Compute Cloud (Amazon EC2) - From their website "Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides resizable compute capacity in the cloud. It is designed to make web-scale computing easier for developers." In short, virtual servers on demand.
Questions:
- How many links between bit.ly/a and bit.ly/zzzzzz are actually in use?
- What is the most linked to domain name?
- What is the most linked to TLD?
- What kind of websites are people URL shortening through bit.ly?
- What privacy concerns might one run in to by URL shortening through bit.ly?
- Are there "bad" links provided through bit.ly? If so, how can one protect against them?
- Is the Bit.ly mascot a lame rip of the OpenBSD mascot?
Starting out: Are you scared of spiders?
To do this, I need a way to get the information, a place to store it, a way to analyze it, and possibly a way to share the data.
The only obvious solution for gathering data is to use a spider. I have used several commercial and FOSS ones the past few years and could not think of any that would be easy to implement for data mining like this. I could be wrong, but instead of spending hours to find out, just spend an hour or two making one. Perl is the language I will be using and I have never made one before. After making a new CentOS 5.4 VM and installing Perl on it, it took about an hour to have a script that would access bit.ly, get the redirected URL, and then store that information in a database. The new problem that showed up was how to generate the bit.ly URL's. Quickly wrote a couple of nested for loops in perl and sent it all to a database. Here is my schema:
mysql> show columns from bitlydata;
| Field | Type | Null | Key | Default | Extra |
| id | int | No | PRI | NULL | auto_increment |
| bitlyurl | text | Yes | NULL | ||
| resulturl | text | Yes | NULL | ||
| resultdata | blob | Yes | NULL | ||
| extra | blob | Yes | NULL |
Horrible? Yes. Does the job? Yes. Total database size with a-z character set and up to 5 characters? 247MB (247132600 bytes). Total rows? 12,356,630. Time to create? About 64 minutes. The "resultdata" column I was going to retrieve all the HTML from the pages in addition to their URL's. After a short preliminary test I decided this was not feasible as it could take anywhere from 1 second to 2 minutes to get the data. The "extra" column I was going to put a timestamp originally, but then decided it was useless as the bit.ly links should not change as far as I could tell so it was renamed extra in the event I wanted to store something there, whatever.
So how does the spider work? Quick quasi-pseudo code is as follows:
- bitlycrawler.pl called with id ranges to scan (ie: bitlycrawler.pl 0 100)
- Pulls all the needed bit.ly URL's from the database.
- Create a LWP::UserAgent, which basically gives you tools through the perl engine to emulate a real browser.
- Iterate through each bit.ly URL and recover the forwarded URL.
- Save the discovered URL in the database.
- Repeat.
Searched for http://bit.ly/aaofp and found this url: http://www.meneame.net/story/dos-rockeros-unica-inspiracion Updated database.
Tests showed it took about 2 seconds per query, so I modified the UserAgent to have a timeout of half a second. This dropped down the results to about a second a query. If I ran two of the scripts at the same time (on the same machine) I could still get about a second a query. If I ran it three times at once, I would get about 1.3 seconds a query. Four simultaneously took the time to about 2.5 seconds a lookup, three seemed to be about the optimum number.
First result set: Analyze this.
To see if this was even worth continuing, I created an initial result set of 10,000 queries because it seemed like a good number. Total size of DB at this time: 247245448 bytes. This is http://bit.ly/a through http://bit.ly/aaofs. The only problem is, how to analyze it. Looks like it is time for some regular expressions.
After some perl, CSV's, and open office love here are the results of the first 10,000 bit.ly's scanned:
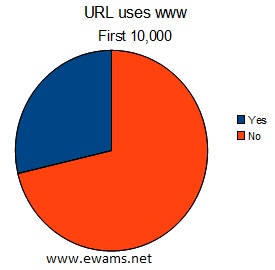 | Pie chart comparing the usage of URL's that use "www" before their address or not. Yes - 2866 total or ~28% No - 7131 total or ~71% |
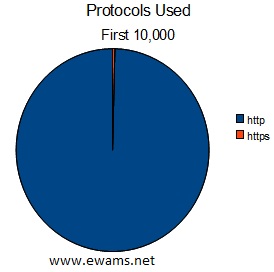 | Pie chart comparing the protocol used in the URL's. http - 9959 total or ~99% https - 38 total or <1% |
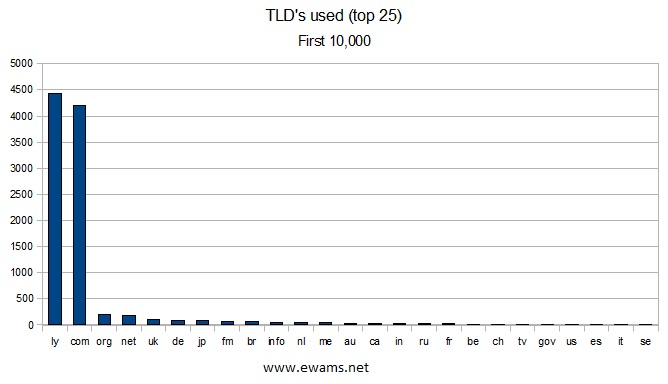 |
| Graph showing the top 25 TLD's used. There were a total of 83 TLD's discovered. 22 were used only once. 9 were used twice. 8 were used three times. 4 were used four times. 5 were used five times. Only 5 TLD's had a recurrence of more than 1% of the total. The TLD's ".ly" and ".com" were used ~44% and ~42% respectively. It is worth noting that the .ly's are because not all of the URL's are in use, example: http://bit.ly/aaaac. There were 22 TLD's that were not legitimate, ie .187 (used twice) and several that were badly formatted URL's. |
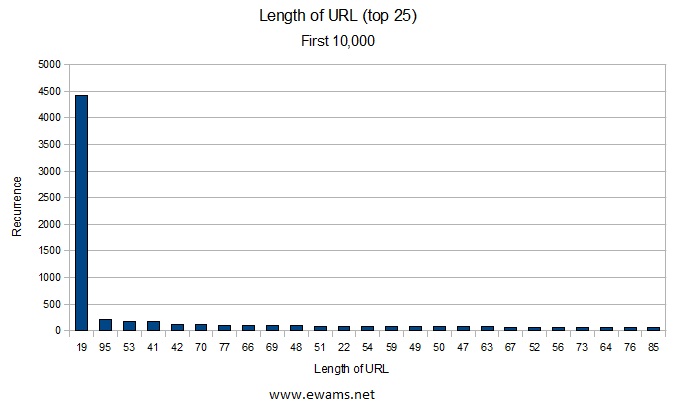 |
| Graph showing the top 25 URL lengths. 19 comes out on top because the sample size used contained mostly 5 character bit.ly addresses, and if they are not in use the result URL is the same as the starting URL (like from above: http://bit.ly/aaaac). The shortest URL was 10 characters (only used once) and the longest was 2049 characters (used 3 times). There were 1148 URL's with 100 or more characters. There were 14 URL's with 500 or more characters. |
| Listing of the top 25 domains used. The first time I plotted domains used I noticed some people were using www and others weren't, hence my first graph. For the results in this round I did not modify the data, so there are some URL's that are going to www.twitter.com/whatever and others going to twitter.com/whatever. There were a total of 2901 unique domains used. 2484 of them were used only once. 203 were used twice. 60 were used three times. 39 were used four times. 20 were used five times. Bit.ly can be explained per the URL not in use result as from the last two graphs. twitter.com is expected as the reason bit.ly was created was for use with twitter. The searchguide.tds.net results are per the URL being invalid and my ISP trying to do a websearch to fix my error. Which makes 30 of the bit.ly addresses tested as possible invalid forwards. It appears most of the websites linked through bit.ly are either social networking related or media related. The exception being www.redcarpetdiamonds.com which is a wedding planning site, not sure of how to classify this webpage. |
Trucking on: Or rather, how to?
It takes approximately 1.3 seconds per query if I run 3 instances simultaneously from my dual core T61. My quad core desktop is out of commission, and I think if I ran both at the same time I might upset my router or ISP, or possibly both. Before undertaking this puzzle of sorts I had been wanting to find a use for Amazon's Elastic Compute Cloud (aka EC2) service, especially after reading Todd Hoff's article on how MySpace.com did some stress testing using EC2. There is also the constraint of time, 12,356,630 addresses would take an estimated 62 days with my current methods. So lets change our approach and put the spider in the cloud.
Here is the estimated architecture:
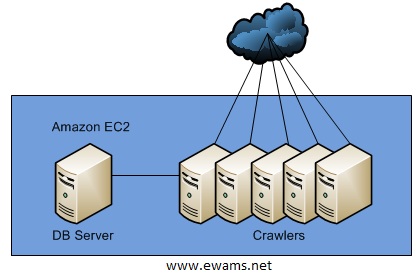
The database box will be a Large Instance 7.5 GB of memory, 4 CPU, 850 GB storage, FedoraCore 8 x64.
The worker machines will be comprised of Small Instances. 1.7 GB of memory, 1 CPU, FedoraCore 8 x32.
I have chosen the magical number five to prevent from being irresponsible and hurting bit.ly; their robots.txt file is rather welcome to spiders though, but nevertheless I do not want to risk being "that guy."
Setting up five instances took less than 30 minutes and I had my spider running within 45 minutes of signing up for the service. Initial results seemed promising (100,000 results in less than 2 hours) but I was actually hurting my large instance and locking the database with the way things were running. The spider also required manual intervention to kick off crawls. We have 12+ million URL's to crawl, this is sloppy, time for some optimizing. Time for sleep.
Renewed methods (unleash the beast)
Step 1: Automate.
Created a job list table on the database server. This would allow a worker to query the available jobs and be returned with a range of URL's that have not been tested. It also has a job status so we know which jobs are currently running or are complete. The effects of this are quite positive: if a job set fails it will be easy to recover and re-run that URL range. It makes the queries on the result set database smaller and also less data the crawlers have to keep in memory. And the best part is all I have to do is run crawler.pl without any command line arguments or babying! (FYI, I broke the job range up into batches of 1000 URL's. No math behind it, just pulled out of thin air).
Step 2: Optimize Database.
When using MySQL it is always a habit of mine to configure the default table type to InnoDB (key feature: row level locking) but forgot to do this when I installed MySQL on the large instance. This resulted in the default table database engine to MyISAM (key feature: table level locking). I also removed the extra columns that were not going to be used for this little bundle of curiosity. The last part, when I kicked off a few crawls while doing some benchmarks I noticed a URL from bit.ly was an attempt of SQL injection. By chance [a fault of mine] it actually failed and did not parse "'); drop table" correctly but I did not feel like taking any chances. The crawler has been updated to prevent such taint come to fruition.
Step 3: Optimal number of spiders
| Workers | crawler.pl per Worker | Average time (sec) | Total throughput (URL/sec) | Est Completion (days) | Est Cost (USD) |
| 1 | 1 | 533 | 1.876 | 76.23 | $777.55 |
| 1 | 2 | 545 | 3.669 | 38.97 | $397.50 |
| 1 | 3 | 577 | 5.199 | 27.5 | $280.50 |
| 1 | 4 | 680 | 5.882 | 24.31 | $247.96 |
| 1 | 5 | 894 | 5.592 | 25.57 | $260.81 |
| 3 | 3 | 586 | 15.358 | 9.31 | $132.95 |
| 3 | 4 | 1158.9 | 10.35 | 13.81 | $197.21 |
| 5 | 1 | 919.2 | 5.43 | 26.33 | $483.42 |
| 5 | 4 | 2864.33 | 6.98 | 20.48 | $376.02 |
Header details:
Workers - The count EC2 small instances running.
crawler.pl per Worker - The number of crawler.pl's running concurrently on each worker.
Average time (sec) - The average time it took each worker to complete each batch of 1,000 URL's
Total throughput (URL/sec) - The average number of URL's being processed per second.
Est Completion (days) - The estimated number of days it would take to process all 12,356,630 targeted URL's.
Est Cost (USD) - The estimated cost of the defined architecture to complete all processing.
Comments:
The first few times I ran the script I was not sure what the results would be and was semi-impressed that it was even working. When running the single worker I figured the length of time was the result of http transmission between bit.ly and the workers. Then when I ran it with 4 and then 5 instances on the same worker I knew SQL was stepping all over itself. The additional tests confirmed it, especially the 5 workers with only 1 instance of crawler.pl. I will not be waiting a month to get my data collected. The only problem is, I have no measurements and my conclusion is based on gut and experience. The beast must be tamed.
Additional:
Average time (sec) results were rounded. The other calculations were truncated.
mysqld CPU usage for all instances with only 1 worker was between average 1%, bounce between 0 and 3%, peaks of 5%.
mysqld CPU usage for all instances with 3 workers was between average 75%, bounce between 45% and 85%, peaks at 100% rarely.
Costs: $0.085 per small instance hour (1 worker only). $0.34 per large instance hour (the DB server only). $0.765 per full architecture hour (5 worker 1 DB). $18.36 per full architecture day (5 worker 1 DB).
Each crawler.pl instance always took up ~10.5MB of RAM and 0-3% of CPU on the worker.
Unicorn Sighted
Without going into the boring details of my mistakes and some new techniques I learned, here is the quickie: SQL statement optimization by reducing queries by 600% per batch job. Improving the worker queue. Creating new measurement data within the application itself. Here are the results after optimize round 2:
| Workers | crawler.pl per Worker | Average time (sec) | Total throughput (URL/sec) |
| 1 | 1 | 454 | 2.2 |
| 1 | 3 | 465 | 6.45 |
| 5 | 3 | 546.31 | 27.45 |
| 5 | 4 | 644.16 | 31.04 |
To not jump the gun, I kicked off 4 instances of crawler.pl on 5 workers and let it sit for an hour. Sure enough 20-25 jobs in the happy warm feeling goes away. Here are the results:
| Workers | crawler.pl per Worker | Average time (sec) | Total throughput (URL/sec) | Est Completion (days) | Est Cost (USD) |
| 5 | 4 | 1264.03 | 15.82 | ? | ? |
Work #128: Task completed by crawler # 1693.
Work #128: Completed work for 127000 to 127999 in 1112 seconds.
Work #128: Cache population time took 0 seconds.
Work #128: Web crawl time took 1094 seconds.
Work #128: Database update time took 9 seconds.
Work #128: Slept on the job a total of 21 seconds.
98% of the time is from web crawling. But hang on, I specified that timeout for each URL lookup to be half a second, so how come it is taking more than a second for each query? CPU and memory on all workers is nominal usage. Possibly overhead from the cache? Memory leak? Network throttling? Connection cache or limit in Perl? Something else? So lets try changing the batch size to 250 URL's.
Changing the batch size has not fixed the problem. It is possible that LWP::UserAgent is not the best module to use for so many connections? Will have to research possible work around (like connections->rest or just a new useragent per batch?). Bad results are repeatable, first run is good time, second run is ok but not as good, third run is progressively worse, forth round of the run is horrible and it never improves. This is regardless of how many crawler.pl are running.
If at first you don't succeed...
I took a break for a day and took a fresh look at everything. After some enabling verbose mode on my crawlers I noticed that it was scanning every URL that it was ever assigned, not just the current batch. The problem? I forgot to clear the cache, it was just adding to its local cache of things to do. I hope someone laughs at this. Here are the new performance results:
| Workers | crawler.pl per Worker | Average time (sec) | Total throughput (URL/sec) | Est Completion (days) | Est Cost (USD) |
| 1 | 1 | 142.5 | 1.75 | 81.72 | 833.55 |
| 1 | 4 | 135 | 7.40 | 19.32 | 197.07 |
| 5 | 4 | 137.72 | 36.30 | 3.93 | 72.15 |
Note that batch sized was changed to 250 URL's a job, so the average time is much lower but the other columns are equal comparison of previous tables.
HAHA! Oh that feels good. So now, it appears we can add more workers and scripts without adding the average time to complete a batch and gives us nothing but sexy results. What is the theoretically "sweet spot" to minimize cost and time?
| Workers | crawler.pl per Worker | Average time (sec) | Total throughput (URL/sec) | Est Completion (days) | Est Cost (USD) |
| 5 | 4 | 140 | 35.71 | 4 | 73.52 |
| 6 | 4 | 140 | 42.86 | 3.34 | 68.08 |
| 7 | 4 | 140 | 50 | 2.86 | 64.19 |
| 8 | 4 | 140 | 57.14 | 2.5 | 61.27 |
| 9 | 4 | 140 | 64.29 | 2.22 | 59 |
| 10 | 4 | 140 | 71.43 | 2 | 57.18 |
| 11 | 4 | 140 | 78.57 | 1.82 | 55.7 |
| 12 | 4 | 140 | 85.71 | 1.67 | 54.46 |
| 13 | 4 | 140 | 92.86 | 1.54 | 53.41 |
| 14 | 4 | 140 | 100 | 1.43 | 52.52 |
| 15 | 4 | 140 | 107.14 | 1.33 | 51.74 |
| 16 | 4 | 140 | 114.29 | 1.25 | 51.06 |
| 17 | 4 | 140 | 121.43 | 1.18 | 50.46 |
| 18 | 4 | 140 | 128.57 | 1.11 | 49.92 |
| 19 | 4 | 140 | 135.71 | 1.05 | 49.44 |
| 20 | 4 | 140 | 142.86 | 1 | 49.01 |
| 21 | 4 | 140 | 150 | 0.95 | 48.63 |
| 210 | 4 | 140 | 1500 | 0.1 | 41.62 |
| 482 | 4 | 140 | 3442.86 | 0.04 | 41.18 |
So how many crawlers can we have on each worker machine until it has detrimental effects?
| Workers | crawler.pl per Worker | Average time (sec) | Total throughput (URL/sec) | Est Completion (days) | Est Cost (USD) |
| 5 | 4 | 140 | 35.71 | 4 | 73.52 |
| 5 | 5 | 133.77 | 46.72 | 3.06 | 56.2 |
| 5 | 6 | 134.84 | 55.62 | 2.57 | 47.21 |
| 5 | 7 | 137.08 | 63.83 | 2.24 | 41.14 |
| 5 | 8 | 140.65 | 71.1 | 2.01 | 36.93 |
| 5 | 9 | 135.79 | 82.85 | 1.73 | 31.69 |
CPU on the database server is running at 0-2% CPU, peaks at 3-4% every so often at only 40MB. The workers are running at a constant 1-8% CPU and still only 10.5MB per worker process (about 95MB total). I am actually very tempted to change the database server to a small instance to save money but I don't really want to perform the migration, too lazy. If Amazon offered a "really small" server I am sure this script could be running on it no problem, as long as it had a highspeed connection.
I wrote a "back off" functionality in to the script to reduce database load on the second day. With 9 concurrent spiders running on a single worker the back off on each script runs almost at least once, sometimes 3 or 4. It appears this is about the maximum number we can run. I have also verified that it is still getting results and appears to be functioning correctly. Adding more workers at this point would reduce cost by only about a dollar each and it takes about 15-20 minute to get a worker set up, I feel that we have reached equilibrium. So, time to wait about a day and a half for the results to be complete and time for some analysis!
Second result set
I did not mention before, but the bit.ly URL's checked for this project (a-zzzzz) were chosen instead of all 6 characters that bit.ly uses is because 12 million is a whole lot easier to check than 8 billion. Not to mention that bit.ly uses a character set of a..z, A..Z and 0..9 which is over 60 billion of possible URL's to check, maybe next time. Without further ado here are the results for a-zzzzz bit.ly URL scan:
Total URL crawling work seconds: 6861409
Total URL crawling work hours: 1905.95
Total URL crawling work days: 79.41
Total stat generation time: 3995 seconds
Database size: 946MB
Out of 12,356,630 URL's checked, 12,348,863 were considered valid and 7767 were considered invalid (~.062% bad URL's). For example, http://bit.ly/aasqz forwards you to "http://lebron james."
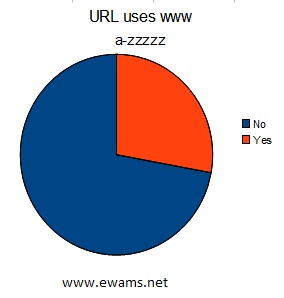 | Pie chart comparing the usage of URL's that use "www" before their address or not. Yes - 3,445,443 or ~28% No - 8,910,852 or ~72% These results are almost exactly the same as the first 10,000. |
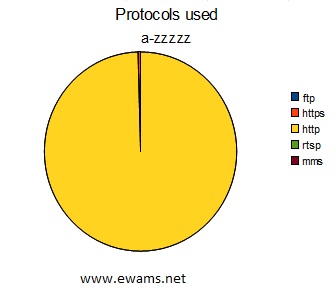 | Pie chart comparing the protocol used in the URL's. ftp - 56 or ~.00045% https - 51474 or ~.41% http - 12304744 or ~99.58% rtsp - 8 or ~.000065% mms - 13 or ~.0001% |
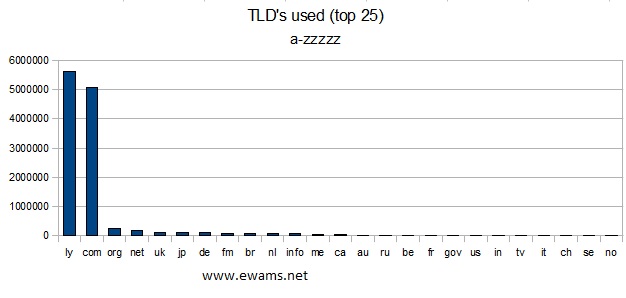 |
| Graph showing the top 25 TLD's used. |
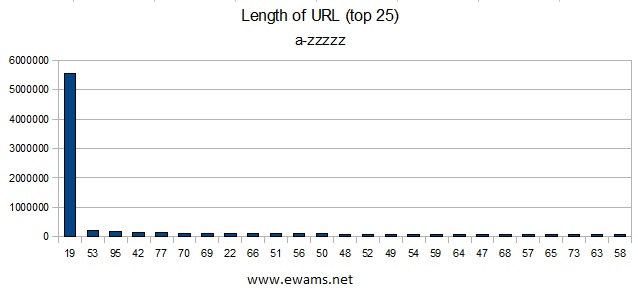 |
| Graph showing the top 25 URL lengths. 19 comes out on top because the sample size used contained mostly 5 character bit.ly addresses, and if they are not in use the result URL is the same as the starting URL (like from above: http://bit.ly/aaaac), which is 19 characters. The shortest URL was 7 characters (used 15 times) and the longest was 5130 characters (used once). There were 1,435,089 URL's with more than 100 characters and 13909 with 500 or more characters. There were a total of 1837 different URL lengths found. |
| Listing of the top 25 domains used. I removed all www. from the results this time and combined them, making www.twitter.com/whatever the same as twitter.com/whatever. Social networking still takes the top usage but not to be forgotten are merchants and a service that I was expecting to take advantage of bit.ly: Google maps. In all, there were 621,089 unique domain names. Sorry redcarpetdiamonds, you came in at 42nd place this time. |
Third result set
The second result set is good information, but the results include over 5.6 million unused URL's that just point right back to bit.ly. This result set contains only bitly's that forward to a site other than bit.ly.
Out of 12,356,630 URL's checked this set contains 6,739,610 URL's in the analysis.
Total stat generation time: 1388 seconds
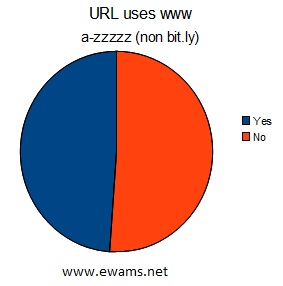 | Pie chart comparing the usage of URL's that use "www" before their address or not. Yes - 3,294,167 or ~48.87% No - 3,445,443 or ~51.12% After cleaning up the results by removing bit.ly addresses this chart has changed drastically. Roughly split down the middle, instead of 3/4 not using www in their addressing scheme. |
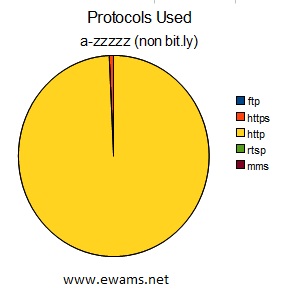 | Pie chart comparing the protocol used in the URL's. ftp - 56 or ~.00083% https - 51,474 or ~.76% http - 6,688,059 or ~99.23% rtsp - 8 or ~.00011% mms - 13 or ~.00019% The results of this view do not change but a few fractions of a percent. Because all http://bit.ly URL's were removed from the result set the total number of URL's using the HTTP protocol changed, but the percentage of the total barely moved. |
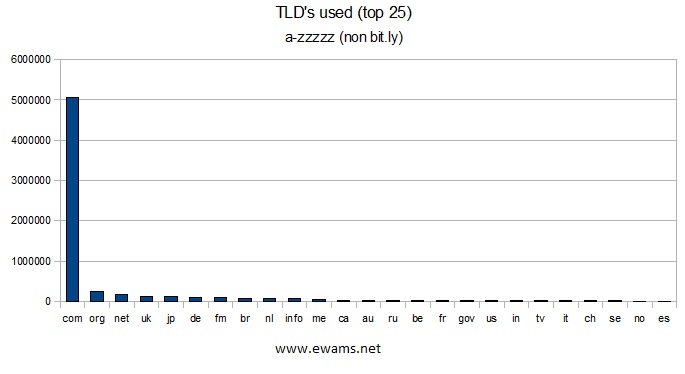 |
| Graph showing the top 25 TLD's used. Nothing unexpected changed from this graph. The .ly TLD has moved down to the 70th position with only 1,502 uses. |
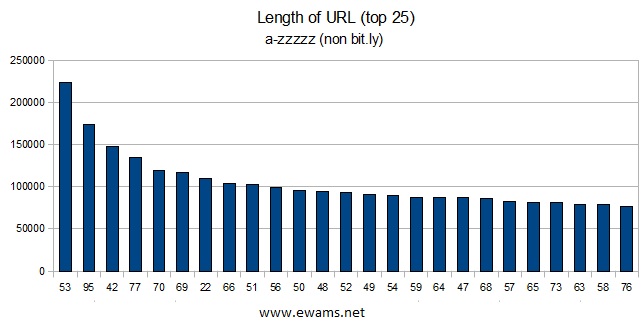 |
| Graph showing the top 25 URL lengths. The length of 19 characters is now in 146th position with 7,518 occurences. |
| Listing of the top 25 domains used. |
| Listing of the top 25 parent domains used. This graph has stripped all of the subdomains and counted everything under its parent domain. (IE maps.google.com and mail.google.com are counted with google.com). It is interesting to note that of the top 25 domains, 4 are country specific. Eight of the domains appearing in this list were not present in the original that did contain subdomains: blogspot.com, co.uk, com.br, yahoo.com, myloc.me, craigslist.org, wordpress.com, and com.au. The top several domains did not change much, but sites like facebook.com and google.com nearly doubled in count. Notice also that the percentage of total is very low. These top 25 domains only account for a third of total unique domains, of which there were 381,666. |
Answers to the questions
- How many links between bit.ly/a and bit.ly/zzzzzz are actually in use?
At the time of the scan, March 14-16th 2010, and within the bit.ly URL range a-zzzzz there are 6,739,905 in use, about 55%. - What is the most linked to domain name?
The most linked to domain in this bit.ly scan was twitter.com with 272,798 total occurences, or about 4% of the total. - What is the most linked to TLD?
Dot com stole the show as the most used TLD. In total there were 5,049,403 URL's with com as the TLD, which is about 75% of the toal. - What kind of websites are people URL shortening through bit.ly?
Almost every site in the top 25 is a social networking website. Not surprising if you think about bit.ly's history as launching for a need in the social networking space.
While sorting through all of the results, a vast majority of the websites linked to are blogs, videos, or pictures. The other large contender is merchants; such as bidding sites, traveling, and regular online stores. Missing from the top of the list was a group I was expecting, new organizations. CNN came in at 58th with 10,306 links, the BBC had 0 links, BBC America had 11, and Fox News was at 181th position with 2,963 links.
There are several oddballs in there, for example I found several bit.ly's that forwarded to what appeared to be SSH keys. The URL forwarded was not a website at all, just the characters forming the key. Others include stories, random words (ie: lebron james), political statements, and just random characters with no obvious meaning. Bit.ly may not know it, but they are also a communication platform!
For the most part, bit.ly is being used how the site intended it: to provide shortened URL's for users to more easily share links with their friends or the world. - What privacy concerns might one run in to by URL shortening through bit.ly?
Privacy and security are as always on the Internet, a joke. When the majority of people use bit.ly they must think that because the URL is obfuscated and the URL generated is "random" that no one will find the page they are linking to. Little do they know that anyone could find their webpage, even if they weren't using bit.ly. Security through obscurity is not security, it is just delaying the inevitable. The problem that Bit.ly's service brings to the table in terms of privacy is also its main strength: making information that much easier to spread.
What am I talking about? The fourth flickr image in the result set was a self nude picture of a female. The second Facebook page linked was for a "private" event, listing the host's full name, address, and telephone number. The list goes on. This is not Bit.ly's fault and there is nothing, short of closing their service, they could do that would stop it. Nor is it even Facebook, flickr, or Blogspot's fault. Is this even a problem though? To me, yes, it is. To others, maybe not, maybe there is a different way to look at it. People on the Internet don't expect privacy or maybe they really want anyone and everyone to view their nude photos, to call them in the middle of the night, or show up at their parties.
This is not of course the only privacy problem. I did not analyze the method that bit.ly stores links for unregistered users, though even after 2 months it still remembered which links I had created, which could mean there is an opportunity for a cookie or session hack to grab those URL's. Nor did I create an account and see if SSL was used, how accounts were managed, or if user passwords were encrypted, as it was beyond the scope of this research. - Are there "bad" links provided through bit.ly? If so, how can one protect against them?
Yes there are bad links, and Bit.ly deserves some praise here. I am defining a bad link as a page with malicious intent, whether it be to download some form of malware, to exploit a browser, or just take advantage of the user to some extent. It would be very hard for me to come up with a method to detect pages containing viruses, javascript exploits, and the like, but thankfully I ran in to a pleasant surprise. Bit.ly has its own method of detecting malicious websites, and if they find one, they warn the user before allowing them to continue.
I detected 30,698 "warning" URL's from bit.ly, like bit.ly/aaaai (Go to at your own risk) which brings you to a page on bit.ly's website stating that it is believed the link is malicious and you should use caution. More information about Bit.ly's anti-malicious initiative can be found on this page from Bit.ly's blog.
A bot herder could use Bit.ly as a control platform, for example I made this, http://bit.ly/aeOaUr, which tells my imaginary botnet to continue spamming, when to check in next, and what bit.ly URL to use for next check in. The next one they go to could tell the botnet to DOS a website or service. Or it could forward them to a webpage with code updates, more explicit instructions, etc.
To prevent from going to a website that you don't want to is simple: don't use Bit.ly's service. This maybe be difficult pending the situation. In which case, ask the person providing the Bit.ly link to give you the direct URL instead. This way you know the intended URL as you can read it before accessing it. - Is the Bit.ly mascot a lame rip of the OpenBSD mascot?
Obviously.
Conclusion:
Bit.ly provides a URL shortening service that, through my analysis of over 12 million bitlys, has shed light on usage patterns, privacy, and the overall social networking scene. Primarily bit.ly is used in the social networking circle of the web, with the main sites linked to being blogs, messages, images, videos, and music. The runner up for usage is merchants, such as eBay, craiglists, Amazon, and etsy. Have you ever tried sending your friend a link from one of those sites, only to find part of the URL gets cut off because they are so long or it contains funky characters? Bit.ly to the rescue! The final observation is that Bit.ly's service is not only used by Americans or English only speakers, but from all over the world: Germans, Britains, the Japanese, and even Australians use it.
I had no idea that pornography and the iPad would lead me down this road with Bit.ly. I was able to generate over a gigabyte of data, create a custom web crawler, try out EC2, brush up on my Perl and SQL skills, and learn a little bit about the tubes on the way. In the future I think it might be interesting to perform this scan on more bitly's, to compare the original bit.ly scan with a new one to see if any changes occur, and maybe perform more analysis on the websites being linked to. Perhaps even compare scans between the URL shortening services out there. Bit.ly, what can you give us? Apparently a lot.
Software used:
- FedoraCore 8
- CentOS 5.4
- MySQL 5.1
- Perl 5
- VMware Workstation 7.1
- WinSCP 4
- OpenOffice 3.2
- phpDesigner 7
- Notepad 6.1
And I leave you with something rather entertaining: http://bit.ly/Gettysburg-Address by D.T.
Sources:
I big thank you to everyone who's information I used to perform the work on this project and to increase my knowledge.
- Sean M. Burke and his book Perl & LWP. The digital version is here: http://lwp.interglacial.com/index.html Accessed 3-13-010
- Unknown author. "Subroutines" http://www.faqs.org/docs/pperl/pickingUpPerl_8.html Accessed 3-13-010
- Gisle Aas on CPAN. "LWP::UserAgent" http://search.cpan.org/~gaas/libwww-perl-5.834/lib/LWP/UserAgent.pm Accessed 3-13-010.
- Unknown author. "Perl and the DBI module" http://www.tizag.com/perlT/perldbiquery.php Accessed 3-13-010
- Alex Batko. "Perl Hash" http://www.cs.mcgill.ca/~abatko/computers/programming/perl/howto/hash/ Accessed 3-13-010
- Dan Sugalski. "perlthrtut - tutorial on threads in Perl" http://www.xav.com/perl/lib/Pod/perlthrtut.html Accessed 3-13-010
- Todd Hoff. "How MySpace Tested Their Live Site with 1 Million Concurrent Users" http://highscalability.com/blog/2010/3/4/how-myspace-tested-their-live-site-with-1-million-concurrent.html Accessed 3-14-010
- Unknown author. "Amazon Elastic Compute Cloud" http://aws.amazon.com/ec2/ Accessed 3-14-010
- Unknown author. "Amazon Elastic Compute Cloud User Guide" http://docs.amazonwebservices.com/AWSEC2/2009-11-30/UserGuide/ Accessed 3-14-010
- Unknown author. "MySQL Overview of Numeric Types" http://dev.mysql.com/doc/refman/5.0/en/numeric-type-overview.html Accessed 3-15-010
Written by Eric Wamsley
Posted: September 6th, 2010 6:40pm
Posted: September 6th, 2010 6:40pm